Capturing Application StateとEphemeral Containers for Debugging Kubernetesに関する以前のブログでは、特定のツールを導入して後の分析のために診断を収集する一方で、インシデントの対応者にインフラやアプリの問題を解決する手段を提供できることの価値について説明しました。
これにより、サービスをできるだけ早く復旧させる必要性と、後の恒久的な解決のために十分なデバッグデータを確保する必要性のバランスがとれ、同時に開発チームはコンテナを無駄なく、パフォーマンス高く稼働させられます。
インシデント発生時にアプリと環境の両方の状態をキャプチャーすることで、レスポンダーやサービスオーナーがツール、認証情報、環境の間でコンテキストを切り替える時間を短縮し、より正確で迅速な対応と問題解決を可能にします。
このシリーズの以前のブログでは、Kubernetesのような最新のクラウドネイティブなプラットフォームや、コンテナ、特にデバッグツールがネイティブに搭載されていないコンテナに必要な独自のアプローチに焦点を当てた技術を説明しました。
全てのアプリをクラウドネイティブに移行できるわけでもなく、多くの人がコンテナ化されたアプリと従来のアプリの両方のハイブリッドシナリオの中で仕事を続けています。
コンテナの一時的な性質やコンテナイメージの厳格なポリシーを抜きにしても、将来のインシデント発生を回避するため、根本原因分析に役立つ瞬時の証拠を取得する必要性があることは確かです。
障害発生時やパフォーマンス低下時に自動的に状態をキャプチャーする機能を説明するユースケースを確認し、興味深いシナリオをピックアップして深く掘り下げてみましょう。
これは網羅的なリストではありませんが、従来のアプリ環境でデバッグ状態キャプチャーがどのように使用されているか、いくつかの例をご紹介します。
インフラとネットワーク
- 1つまたは複数のインフラ・コンポーネント上でリソースを消費するトッププロセス
- TCPダンプ、スレッド/メモリ/コアダンプ
データベース
- 最も多くのリソースを消費するクエリー
- 現在のクエリーの状態
- アプリ固有のクエリーの実行
アプリ固有
- Java – jstackなどのツールでスレッド/ヒープダンプを実行する
- Windows – Proc Dump
- Python – スレッドダンプの実行
- 全て – アプリ固有のログファイル
追加のログファイル
デバッグ状態のキャプチャーは、ログアグリゲーターによってキャプチャーされない可能性のある任意のファイルから、全体または一部のログを取得できます。
PagerDuty Process Automationは、自動診断プロジェクトの一環として、アプリと環境の状態をキャプチャーするための多くの事前構築されたテンプレートワークフローを提供します。これらのワークフローは柔軟で拡張性があるため、特定のユースケースに対応するようにカスタマイズすることが可能です。
さらに深く掘り下げる
ここでは、インシデントの長期的な解決策を特定するために役立つ、環境状態のキャプチャーの具体的な例について詳しく見ていきましょう。
ユースケース1– データベースのデバッグを収集する
Process Automationの SQL RUNステップを使用して、インラインステートメントを追加するか、既存のスクリプトを実行できます。私のアプリはMariaDB(MySQLのフォーク)なので、MySQLクエリー実行のために以下のパラメータを使用できます:
SHOW FULL PROCESSLIST;
(注:クレデンシャルは既存の外部ストアから取得され、ワークフローの一部としてステップを実行するときに安全に渡されるため、情報を公開することなく安全に委譲できます)

その出力をインシデントプラットフォーム(私の場合はもちろんPagerDuty)に渡し、データベースサービス内でインシデントが発生した場合に自動的に収集するようにジョブを設定しています。

この情報は、アプリ、Chatops ツール、またはポストモーテム内で、私のレスポンダーの両方が自動的に利用できるようになりました。この場合、誰かがインシデントの時点でベンチマークテストを実行しているのが分かります!また、以前のブログ記事と同様に、より複雑なバージョンをAWS S3 Bucketのようなストレージ環境に投稿し、後で分析することも容易でしょう。
ユースケース2– アプリのデバッグを収集する
私の可観測性ツールは、アプリがいつ失敗したかをすぐに知らせてくれますが、失敗した理由については必ずしも情報を提供するとは限りません。この2つ目のユースケースは、私のpythonアプリのアドホックコマンドを実行して、私のアプリのサンプリングプロファイラーであるpy-spyを、当社の自動化プラグインの1つと組み合わせて、後で取り出すためにファイルをS3に安全に移動するものです。

データをS3ストレージに直接出力します。

この例では、私のpythonアプリのワーカーの状態をスレッドレベルでハイライトし、そのまま開発者の手元に届き、参照する必要がある限り保存されます。
もちろん、これらのコマンドは排他的なものではなく、複数のチェックを連鎖させてより広範なビューを提供することも簡単にできます。
ユースケース3– 従来のインフラのデバッグ状態のキャプチャー
3つ目のユースケースでは、一連のbashコマンドをリモートマシンにデプロイし、トリガーイベントで再び実行する必要があります。これは主に、開いているファイルやネットワーク接続などの診断を表示しますが、特定の呼び出しをトレースするために使用できるツールbpftraceも実行します:
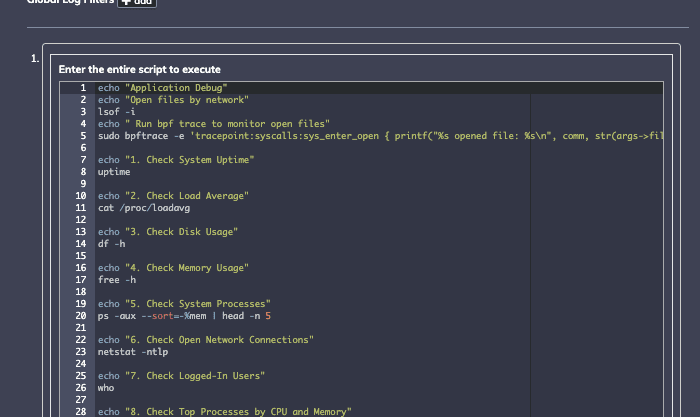
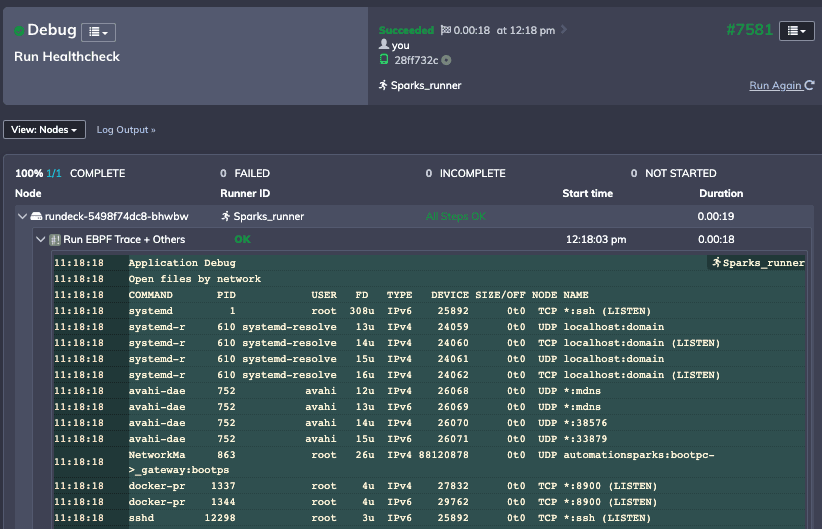
Process Automationでは、スクリプトを定義してデプロイし、その出力を保存して、環境の状態のスナップショットを収集できます:
結論
監視ツールからの信号は、従来の環境であっても、幅広い可視性の恩恵を受け、レスポンダー、DevOps エンジニア、または SRE が迅速かつ安全な意思決定を行えるようになります。また、開発者がすぐに取り掛かれないこともあり、問題が発生したときに追加情報や状態をキャプチャーする機能が必要になるケースも多々あります。
Debug State Captureは、レスポンダーに追加のコンテキストを提供し、さまざまなツールを使いこなす時間を短縮し、その後の分析のためにより深いデータセットを収集する機能を提供します。
もっと詳しく知りたいですか?今すぐRunbook Automationのトライアル版を始めましょう。
この記事はPagerDuty社のウェブサイトで公開されているものをDigital Stacksが日本語に訳したものです。無断複製を禁じます。原文はこちらです。
 カテゴリー :インテグレーション&ガイド
カテゴリー :インテグレーション&ガイド

